
On February 2015, Vint Cerf, also known as the father of the internet, issued a warning to humanity - that of a possible dark age and a lost generation simply because the systems of the future will not be able to render the files of the present.
“We are nonchalantly throwing all of our data into what could become an information black hole without realizing it. We digitise things because we think we will preserve them, but what we don’t understand is that unless we take other steps, those digital versions may not be any better, and may even be worse, than the artifacts that we digitised,”
The decay of files simply because newer software/hardware doesn’t understand the format it was written in is called Bit Rot and happens with every new generation of storage, processors or software that comes along and renders the previous one incompatible and obsolete.
NASA recently stated that they have lost access to tons of data from the early moon landings, because the machines used to read the tapes were scrapped and cannot be rebuilt.
We are losing, in some cases access to a over 80% of scientific data from the early days of computing and often not even realizing it and this is not a problem for some distant future.. we can no longer play many video-games from the 90’s because the consoles are incompatible or the distributors are no longer around. Rapidly changing standards coupled with the fact that we are destroying physical copies of old text while preserving “digital copies” means that we risk erasing not only the chronicles of our time but that of history itself.
Are we falling backwards in time?

The stories of the earliest human-beings etched in stones on the inside of caves have survived over thousands of decades.
When we first started writing, we used clay tablets which survived in some cases for thousands of years, then we switched to a paper medium, it is more convenient to store information on paper but it also decays faster and the only paper writings we find today are the ones which had been carefully preserved through time and in some sense “deemed important”.
Paper writings and clay tablets however did not have a large cost to retrieve data as any one who could read and understand the language could read from the paper material.
In the information age however, there is a cost to storing data at scale - it involves the cost to run servers, pay for electricity and pay for people managing those servers, pay for upgrades when technology advances. There is a cost to retrieve it too, the users need to have hardware and software that can understand and render the format the file was written it.
Formats change, sometime due to technical reasons and other times due to purely political reasons. If Microsoft Word decides to stop supporting the docs format or if the PDF format is no longer accepted as better ones come along and over time hardware and software design takes a different direction.. in that future all of the research papers, financial reports, birth certificates and death certificates stored in pdf will be lost forever.
As we are creating more data, we are also erasing our past often permanently. If a consumer web company gets acquired or liquidates, it has no incentive to keep it’s data centers running as what happened when Home automation company Revolv got acquired by Google Nest and its automation hub was shut down leaving owners of the smart home product feeling pretty dumb about their decision. Similarly a bank or a financial institution may have no incentive to keep transaction records beyond what is needed by business and regulatory requirements.
Consider that almost none of the popular blogs, or social media platforms that we see today will be around in 50 years, it’s hard to imagine what will happen to all the data that these companies would have amassed over the years. The data that would have been chronicles of our life and times.
When every software we use is a service, then our ownership of things and control over them is dictated by the service provider. In an irony only fitting to the title, in 2009 Amazon remotely erased all copies of George Orwell’s 1984 from Kindle devices after a dispute with the publisher.
Gamers are often painfully aware of this fact as they deal with their software and hardware becoming incompatible and games being rendered useless, if Steam shut down it’s servers, millions of players will have no rights to play the game which they purchased. If League Of Legends servers shut down, gamers may never be able to play the game ever again because the strong copyrights ensure that the game servers cannot be recreated. Player’s of Crysis and BattleField 1942 realized this when the titles suddenly became unplayable as GameSpy shut it’s servers. PS3 games are not compatible with PS2 consoles and as support for the software and hardware wanes, any records of the hours of your life you spent playing the game will be gone forever.
A letter may survive hidden inside a closet for a hundred years, but as time passes and a file format and all it’s related knowledge becomes obsolete, no correspondence or journal written in the file format can ever be retrieved..
A brief history of data storage

When we first started writing, we used clay tablets which survived in some cases for thousands of years, then we switched to a paper medium, it is more convenient to store information on paper but it also decays faster and the only paper writings we find today are the ones which had been carefully preserved through time and in some sense “deemed important”.
Paper writings and clay tablets however did not have a large cost to retrieve data as any one who could read and understand the language could read from the paper material.
In the information age however, there is a cost to storing data at scale - it involves the cost to run servers, pay for electricity and pay for people managing those servers, pay for upgrades when technology advances. There is a cost to retrieve it too, the users need to have hardware and software that can understand and render the format the file was written it.
Formats change, sometime due to technical reasons and other times due to purely political reasons. If Microsoft Word decides to stop supporting the docs format or if the PDF format is no longer accepted as better ones come along and over time hardware and software design takes a different direction.. in that future all of the research papers, financial reports, birth certificates and death certificates stored in pdf will be lost forever.
As we are creating more data, we are also erasing our past often permanently. If a consumer web company gets acquired or liquidates, it has no incentive to keep it’s data centers running as what happened when Home automation company Revolv got acquired by Google Nest and its automation hub was shut down leaving owners of the smart home product feeling pretty dumb about their decision. Similarly a bank or a financial institution may have no incentive to keep transaction records beyond what is needed by business and regulatory requirements.
Consider that almost none of the popular blogs, or social media platforms that we see today will be around in 50 years, it’s hard to imagine what will happen to all the data that these companies would have amassed over the years. The data that would have been chronicles of our life and times.
When every software we use is a service, then our ownership of things and control over them is dictated by the service provider. In an irony only fitting to the title, in 2009 Amazon remotely erased all copies of George Orwell’s 1984 from Kindle devices after a dispute with the publisher.
Gamers are often painfully aware of this fact as they deal with their software and hardware becoming incompatible and games being rendered useless, if Steam shut down it’s servers, millions of players will have no rights to play the game which they purchased. If League Of Legends servers shut down, gamers may never be able to play the game ever again because the strong copyrights ensure that the game servers cannot be recreated. Player’s of Crysis and BattleField 1942 realized this when the titles suddenly became unplayable as GameSpy shut it’s servers. PS3 games are not compatible with PS2 consoles and as support for the software and hardware wanes, any records of the hours of your life you spent playing the game will be gone forever.
A letter may survive hidden inside a closet for a hundred years, but as time passes and a file format and all it’s related knowledge becomes obsolete, no correspondence or journal written in the file format can ever be retrieved..
A brief history of data storage
The earliest recording in tablets have survived for thousands of years. Source.
Our earliest ancestors sketched their thoughts in paintings deep inside caves which turned into timeless archives of data guiding humankind forward. When we started to write, we used to write on clay tablet’s which survived for thousands of years and more and more of them are still being found today.
Then in the year 1440 AD, the Gutenburg Printing Press came along and was one of the defining moments in history allowing people to get access to knowledge that was for so long reserved for the elite, spurring the scientific revolutions which have come to define the modern world. The paper medium had a flaw though, paper is a weak material and decays easily. It’s only the most well preserved books that we find that are hundreds of years old.
As we marched on to the information age, and transitioned data storage into a stream of bits stored on servers, we spurred another revolution, the internet.
Our achievements lie in the advancements in information theory and machine learning. We record our lives on Twitter and Facebook and Instagram which stores its data in public clouds or data-centers, we chronicle our work on Github and store it on data-centers of these SAAS vendors.
How are we losing our data?
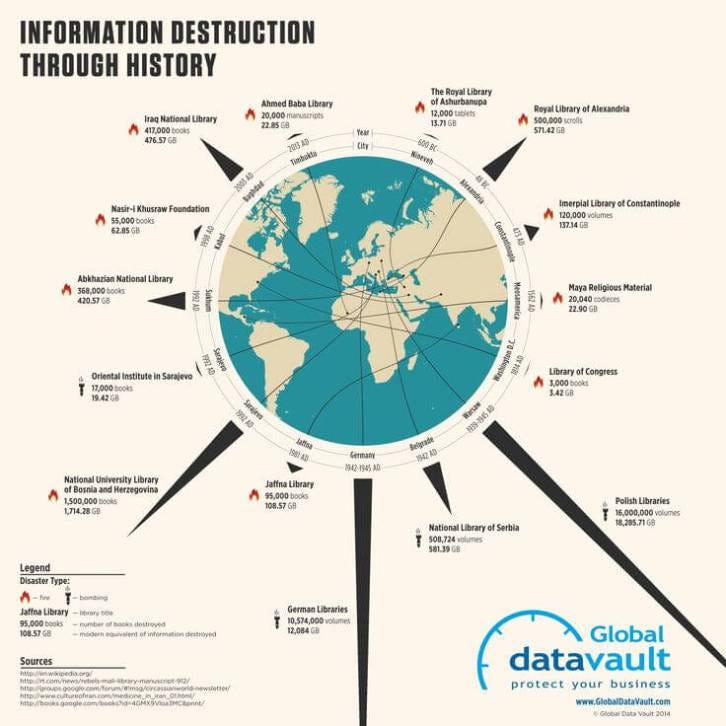
Before we had data-centers we had libraries. Libraries were tasked with keeping catalogues of books and journals considered to be important from the perspective of humanity from the present and the past. These libraries would sometimes survive through centuries, but many of them were destroyed over the years through wars and natural disasters.
Our earliest ancestors sketched their thoughts in paintings deep inside caves which turned into timeless archives of data guiding humankind forward. When we started to write, we used to write on clay tablet’s which survived for thousands of years and more and more of them are still being found today.
Then in the year 1440 AD, the Gutenburg Printing Press came along and was one of the defining moments in history allowing people to get access to knowledge that was for so long reserved for the elite, spurring the scientific revolutions which have come to define the modern world. The paper medium had a flaw though, paper is a weak material and decays easily. It’s only the most well preserved books that we find that are hundreds of years old.
As we marched on to the information age, and transitioned data storage into a stream of bits stored on servers, we spurred another revolution, the internet.
Our achievements lie in the advancements in information theory and machine learning. We record our lives on Twitter and Facebook and Instagram which stores its data in public clouds or data-centers, we chronicle our work on Github and store it on data-centers of these SAAS vendors.
How are we losing our data?
Before we had data-centers we had libraries. Libraries were tasked with keeping catalogues of books and journals considered to be important from the perspective of humanity from the present and the past. These libraries would sometimes survive through centuries, but many of them were destroyed over the years through wars and natural disasters.
The records of books and texts we have lost through history
Changing hardware standards
The Moore’s law states that the number of transistors in an integrated-circuit roughly doubles every two years. Disk-storage and processor power is continually evolving and not always in a backward-compatible way. Often times maintaining backward compatibility simply isn’t possible and other times such efforts are abandoned due to diminishing returns over time.
We are already losing many films and recordings from the pre-VCR era because people simply forgot to transfer the works into newer storage media and the existing works were lost or the format to play them are not supported anymore. To see how disk storage has changed through the years you can check out this link.

Changing hardware standards
The Moore’s law states that the number of transistors in an integrated-circuit roughly doubles every two years. Disk-storage and processor power is continually evolving and not always in a backward-compatible way. Often times maintaining backward compatibility simply isn’t possible and other times such efforts are abandoned due to diminishing returns over time.
We are already losing many films and recordings from the pre-VCR era because people simply forgot to transfer the works into newer storage media and the existing works were lost or the format to play them are not supported anymore. To see how disk storage has changed through the years you can check out this link.
A snapshot of storage hardware through time
Evolving Database APIs and engines
 A snapshot of database API evolution [source]
A snapshot of database API evolution [source]
Database APIs have evolved with the changing nature of data, in the earliest days of computing relational databases where hierarchical, until the the Entity-Relationship model was proposed and resulted in the evolution of the relational database management system. NoSQL systems evolved to serve the data needs in the internet era of unstructured data .
The problem is these APIs are often not compatible with each other . Even variants of SQL provided by different vendors are not drop-in replacements, there are different variants of APIs supported by different vendors and petabytes of data stored in a format which is not compatible with any other API. So if the company backing the API goes out of business, database drivers for popular programming languages will disappear, the data locked in the API will be lost forever even if it has not been actually deleted from the hardware.
Hardware Failures and Human Errors

Evolving Database APIs and engines
A snapshot of database API evolution [source]Database APIs have evolved with the changing nature of data, in the earliest days of computing relational databases where hierarchical, until the the Entity-Relationship model was proposed and resulted in the evolution of the relational database management system. NoSQL systems evolved to serve the data needs in the internet era of unstructured data .
The problem is these APIs are often not compatible with each other . Even variants of SQL provided by different vendors are not drop-in replacements, there are different variants of APIs supported by different vendors and petabytes of data stored in a format which is not compatible with any other API. So if the company backing the API goes out of business, database drivers for popular programming languages will disappear, the data locked in the API will be lost forever even if it has not been actually deleted from the hardware.
Hardware Failures and Human Errors
Predictable reasons for data loss[Source]
Storage hardware often fails, sometimes due to virus or software crashes, other times due to human errors or power outages. Data is lost when your phone hard-drive gets fried, sometimes because it can’t be recovered other times because it may be expensive to do it.
The public cloud: A timeless abstraction of the infrastructure layer (In theory at-least)

Storage hardware often fails, sometimes due to virus or software crashes, other times due to human errors or power outages. Data is lost when your phone hard-drive gets fried, sometimes because it can’t be recovered other times because it may be expensive to do it.
The public cloud: A timeless abstraction of the infrastructure layer (In theory at-least)
The promise of Timeless abstraction over infrastructure layer transcending hardware or API upgrades
We trust that the cloud provider will be timeless and will outlast the market forces and changing technologies and that data stored in the public cloud will be etched forever. We believe that the cloud provider will internally migrate the data to newer boxes if the older ones become obsolete. The cloud provider will maintain replicas and copies against data outages and deal with software migration. But perhaps that is simply not true.
We trust that the cloud provider will be timeless and will outlast the market forces and changing technologies and that data stored in the public cloud will be etched forever. We believe that the cloud provider will internally migrate the data to newer boxes if the older ones become obsolete. The cloud provider will maintain replicas and copies against data outages and deal with software migration. But perhaps that is simply not true.
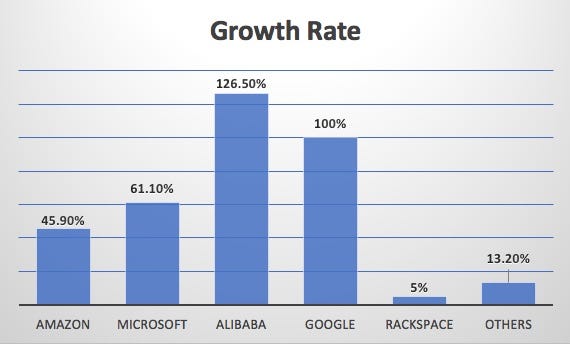
Growth rate for public cloud providers in 2016 [source]
Looking at the global IAAS Market we see many names and start-ups providing “Infrastructure As A Service” solutions. In some sense they will gain and lose market share and with time many names will disappear and new ones will come to take their place and while we may assume that consolidation will happen as giants absorb the smaller ones, we do not know what SLAs will be honored in time with evolving technologies and market-forces.
The idea behind YugaByte
A timeless storage engine, agnostic of Infrastructure or API.
Looking at the global IAAS Market we see many names and start-ups providing “Infrastructure As A Service” solutions. In some sense they will gain and lose market share and with time many names will disappear and new ones will come to take their place and while we may assume that consolidation will happen as giants absorb the smaller ones, we do not know what SLAs will be honored in time with evolving technologies and market-forces.
The idea behind YugaByte
A timeless storage engine, agnostic of Infrastructure or API.
We gave names to the stars and constellations and passed it down the generations.
Yuga represents an era in Sanskrit. The vision behind YugaByte is to build a data layer that is in some sense timeless and indestructible. A few of the founders having built the storage and messaging infrastructure at Facebook and Oracle, uniquely know some of the challenges that companies of tomorrow will face when the scale of petabytes becomes commonplace. The mission-critical data of today will become of the warehouse data of tomorrow and archived data in a few years. We want data to live through changing API’s and hardware specs.We were driven by the following guiding principles-
The data layer must be API agnostic.
A look into the database systems over the past 40 years shows a landscape littered with APIs none of which are compatible with each other. We set out to build a database that is wire-compatible with Redis, CQL and SQL API’s and is equally performant in most use-cases and more performant in focused use-cases than the original storage engine.
The data layer must be hardware agnostic.
Can we completely abstract out the infrastructure layer, provide the same experience on AWS, GCP, or OnPrem providers and eliminate cloud lock-in on the data layer.(I believe kids these days are calling it cloud-native)
Can we add or remove nodes to the data cluster in a hardware agnostic way, Can we use modern devops tooling and containerization to build a solution that completely abstracts out the infrastructure of the IAAS provider.
The data layer must be open-source and compatible with open standards.
An open-source code base and a thriving community of contributors means that the software will outlast most market-forces and evolve to support use-cases which are more fitting to the unknown future.
The data layer must be distributed and fault-tolerant.
Can the data layer tolerate the failure of an arbitrary number of nodes, can we integrate alerting mechanism and metrics natively into the engine so that there is no loss of data due to nodes being down or disks being full. Can we eliminate most ops use-cases for node failure within the orchestration layer itself.
The data layer must natively support async replicas and snapshots.
Can we apply the principles above not just to the primary cluster but also to read replicas, backups and snapshot and make them hardware and API agnostic too in a sense providing perfect mobility between various infrastructure providers.
To answer all these questions, we built the Yugabyte project. It is a continually evolving effort towards achieving data that is in some sense permanent.
If you liked the story, theres 50 ways (claps) to show your appreciation :)
Open source developers live for their stars :)
Show us your love by starring us on Github.
Have a question? join the gitter channel.
Yuga represents an era in Sanskrit. The vision behind YugaByte is to build a data layer that is in some sense timeless and indestructible. A few of the founders having built the storage and messaging infrastructure at Facebook and Oracle, uniquely know some of the challenges that companies of tomorrow will face when the scale of petabytes becomes commonplace. The mission-critical data of today will become of the warehouse data of tomorrow and archived data in a few years. We want data to live through changing API’s and hardware specs.We were driven by the following guiding principles-
The data layer must be API agnostic.
A look into the database systems over the past 40 years shows a landscape littered with APIs none of which are compatible with each other. We set out to build a database that is wire-compatible with Redis, CQL and SQL API’s and is equally performant in most use-cases and more performant in focused use-cases than the original storage engine.
The data layer must be hardware agnostic.
Can we completely abstract out the infrastructure layer, provide the same experience on AWS, GCP, or OnPrem providers and eliminate cloud lock-in on the data layer.(I believe kids these days are calling it cloud-native)
Can we add or remove nodes to the data cluster in a hardware agnostic way, Can we use modern devops tooling and containerization to build a solution that completely abstracts out the infrastructure of the IAAS provider.
The data layer must be open-source and compatible with open standards.
An open-source code base and a thriving community of contributors means that the software will outlast most market-forces and evolve to support use-cases which are more fitting to the unknown future.
The data layer must be distributed and fault-tolerant.
Can the data layer tolerate the failure of an arbitrary number of nodes, can we integrate alerting mechanism and metrics natively into the engine so that there is no loss of data due to nodes being down or disks being full. Can we eliminate most ops use-cases for node failure within the orchestration layer itself.
The data layer must natively support async replicas and snapshots.
Can we apply the principles above not just to the primary cluster but also to read replicas, backups and snapshot and make them hardware and API agnostic too in a sense providing perfect mobility between various infrastructure providers.
To answer all these questions, we built the Yugabyte project. It is a continually evolving effort towards achieving data that is in some sense permanent.
If you liked the story, theres 50 ways (claps) to show your appreciation :)
Open source developers live for their stars :)
Show us your love by starring us on Github.
Have a question? join the gitter channel.
No comments:
Post a Comment